
Table of Contents
A lot has been said and written about scaling PostgreSQL to many cores and subsequently to many machines. Running PostgreSQL in a server farm is something, which has not been possible for many years. However, this has definitely changed. A lot of development has gone into scaling PostgreSQL and to running a single query on many CPUs. PostgreSQL 9.6 was the first release, which allowed to run a query on many nodes. Development has moved on and things are constantly improving to make PostgreSQL even better.
Currently we have some projects going on here at Cybertec, which require PostgreSQL to scale well beyond a single server. The idea to scale PostgreSQL infinitely is of course not new but it is still exciting to push the limits of our beloved Open Source database further and further every day.
Traditionally PostgreSQL used a single CPU core for a query. Of course this used to be a severe limitation, which has fortunately been removed. Many things inside PostgreSQL can already be done in parallel. As the project moves on, more and more parallelism will be available, and many more queries can benefit from multicore systems.
To show how a simple query can benefit from parallelism, we have compiled a simple data structure:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
node=# d t_demo Table 'public.t_demo' Column | Type | Collation | Nullable | Default --------+---------+-----------+----------+------------------------------------ id | integer | | not null | nextval('t_demo_id_seq'::regclass) grp | integer | | | data | real | | | Indexes: 'idx_id' btree (id) |
The query used for this test is pretty: It simply counts the number of rows for each group:
|
1 2 3 4 5 |
SELECT grp, count(data) FROM t_demo GROUP BY 1; |
When running in parallel mode, the best plan produced by the optimizer possible with our version is the following:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
node=# EXPLAIN SELECT grp, partial.count(data) FROM public.t_demo GROUP BY grp; QUERY PLAN -------------------------------------------------------------------------------------------------- Finalize GroupAggregate (cost=635312.96..635314.26 rows=10 width=12) Group Key: grp -> Sort (cost=635312.96..635313.36 rows=160 width=12) Sort Key: grp -> Gather (cost=635291.01..635307.10 rows=160 width=12) Workers Planned: 16 -> Partial HashAggregate (cost=634291.01..634291.10 rows=10 width=12) Group Key: grp -> Parallel Seq Scan on t_demo (cost=0.00..603041.01 rows=6250000 width=8) |
PostgreSQL will process the large table using 16 worker processes. In case your system contains at least 16 CPU cores, performance will basically increase in a linear way as worker processes are added. Each worker will aggregate data and the partial aggregates are then added up. This linear trend is very important because it is a necessary precondition to use hundreds or thousands of CPUs at the same time.
If you have a normal application it is usually sufficient to have a single box because you can aggregate millions of rows in very little time on a single database node. However, if data grows even further, scaling to many nodes might be necessary.
Assuming that our data node contains 16 CPU cores (Google cloud box) and 100 million rows, performance will improve depending on the number of processes used:
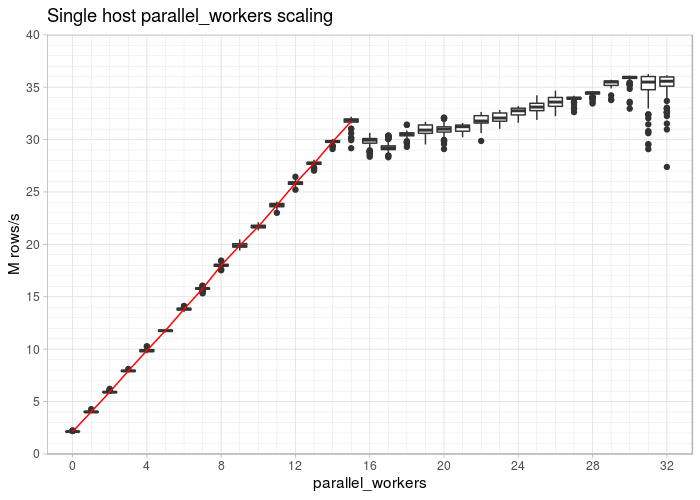
The first important observation is that the line goes straight up to 16 cores. It is also interesting to see that you can still gain a little bit of speed if you are using more than 16 processes to do the job. The benefit you can see here is related to Intel Hyperthreading - you can expect a boost of around 15% given this type of query. On a single database node (VM) you can reach around 40 million rows per second for a simple aggregation.
However, the goal was to reach more than 1 billion rows / second. The way to get there is to add servers.
To reach our goal the following architecture will be used:
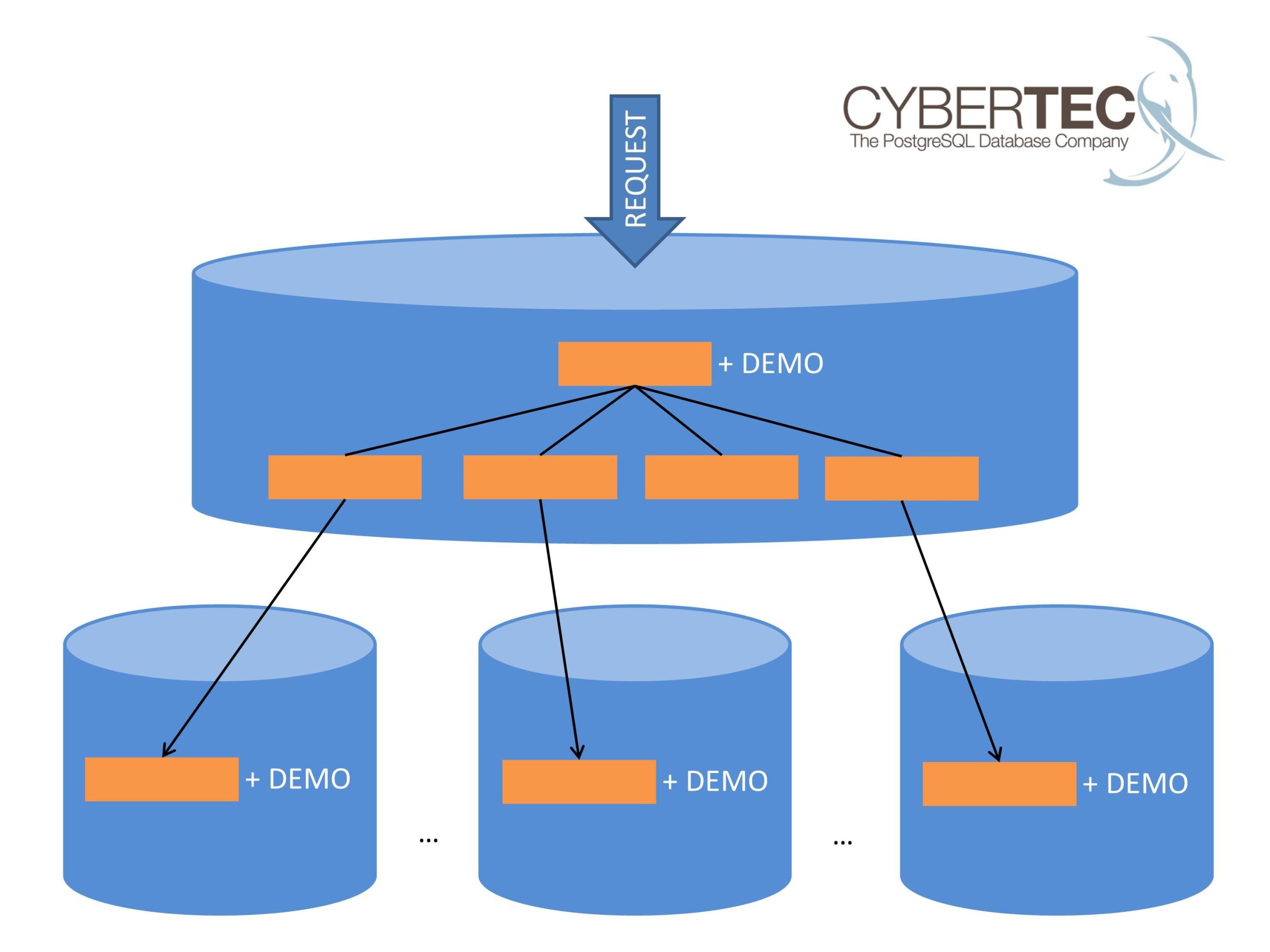
The idea is to have a partitioned table, which is distributed. The data will reside on the actual nodes.
In a first step a second server is added so that we can see that we indeed process twice the amount of data within the same timeframe.
Here is the execution plan:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
EXPLAIN ANALYZE SELECT grp, COUNT(data) FROM t_demo GROUP BY 1; QUERY PLAN ------------------------------------------------------------------------------------------------------------ Finalize HashAggregate (cost=0.02..0.03 rows=1 width=12) (actual time=2706.764..2706.768 rows=10 loops=1) Group Key: t_demo.grp -> Append (cost=0.01..0.01 rows=1 width=0) (actual time=2486.349..2706.735 rows=20 loops=1) -> Foreign Scan (cost=0.00..0.00 rows=0 width=0) (actual time=0.818..0.822 rows=10 loops=1) -> Foreign Scan (cost=0.00..0.00 rows=0 width=0) (actual time=0.755..0.758 rows=10 loops=1) -> Partial HashAggregate (cost=0.01..0.01 rows=1 width=0) (never executed) Group Key: t_demo.grp -> Seq Scan on t_demo (cost=0.00..0.00 rows=1 width=8) (never executed) Planning time: 0.200 ms Execution time: 2710.888 ms |
In this example 100 million rows have been deployed on each database server. The beauty is that the execution time stays the same.
Let us try the same query with 32 x 100 million rows now:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
node=# EXPLAIN ANALYZE SELECT grp, count(data) FROM t_demo GROUP BY 1; QUERY PLAN ------------------------------------------------------------------------------------------------------------ Finalize HashAggregate (cost=0.02..0.03 rows=1 width=12) (actual time=2840.335..2840.340 rows=10 loops=1) Group Key: t_demo.grp -> Append (cost=0.01..0.01 rows=1 width=0) (actual time=2047.930..2840.015 rows=320 loops=1) -> Foreign Scan (cost=0.00..0.00 rows=0 width=0) (actual time=1.050..1.052 rows=10 loops=1) -> Foreign Scan (cost=0.00..0.00 rows=0 width=0) (actual time=1.000..1.002 rows=10 loops=1) -> Foreign Scan (cost=0.00..0.00 rows=0 width=0) (actual time=0.793..0.796 rows=10 loops=1) -> Foreign Scan (cost=0.00..0.00 rows=0 width=0) (actual time=0.776..0.779 rows=10 loops=1) ... -> Foreign Scan (cost=0.00..0.00 rows=0 width=0) (actual time=1.112..1.116 rows=10 loops=1) -> Foreign Scan (cost=0.00..0.00 rows=0 width=0) (actual time=1.537..1.541 rows=10 loops=1) -> Partial HashAggregate (cost=0.01..0.01 rows=1 width=0) (never executed) Group Key: t_demo.grp -> Seq Scan on t_demo (cost=0.00..0.00 rows=1 width=8) (never executed) Planning time: 0.955 ms Execution time: 2910.367 ms |
Wow, we need less than 3 seconds for 3.2 billion rows!
The result looks like this:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
node=# SELECT grp, count(data) FROM t_demo GROUP BY 1; grp | count -----+----------- 6 | 320000000 7 | 320000000 0 | 320000000 9 | 320000000 5 | 320000000 4 | 320000000 3 | 320000000 2 | 320000000 1 | 320000000 8 | 320000000 (10 rows) |
All together there are 3.2 billion rows on those shards.
The most important observation here is that for this kind of query shards can be added on demand as more performance is needed or as the amount of data just grows. PostgreSQL will scale up nicely with every node people add.
So what is actually needed to achieve those results? First of all it does not work with vanilla PostgreSQL 9.6. The first thing we needed was some functionality, which will be in PostgreSQL 10.0: postgres_fdw needs the ability to push down aggregates to a remote host. That is the easy part. The trickier part is to teach PostgreSQL that all shards have to work in parallel. Fortunately there has been a patch out there, which allowed for making “Append” nodes fetch data concurrently. Parallel Append is an important precondition for our code to work.
However, there is more: For many years PostgreSQL could only aggregate data AFTER it has been joined. Basically this restriction has stopped many performance optimizations. Thanks to incredible work done by Kyotaro Horiguchi, who has done a wonderful job removing this restriction, it was possible for us to build on top to aggregate so much data and to actually reach 1 billion rows per second. Given the complexity of the task it is more than necessary to explicitly list Kyotaro's work because without him our achievement would have been close to impossible.
But there is more to making this work: Our solution is heavily based on postgres_fdw. To be able to fetch large amounts of data, postgres_fdw uses a cursor on the remote side. At this point PostgreSQL 9.6 and PostgreSQL 10.0 cannot do cursors fully parallel yet. Therefore we had to lift this restriction to ensure that all CPU cores on the remote hosts can be used at the same time.
Finally it needs a couple of (at this point) handwritten aggregates to do the map-reduce style aggregation here. Achieving that is simple as it can easily be done with a simple extension.
While 1 billion rows per second is certainly a nice achievement, there will be more cool stuff in PostgreSQL in the future. As JIT compilation and various other optimizations start to make their way into PostgreSQL (tuple deforming, column store, etc.), we will see similar results using fewer and fewer CPUs. You will be able to use fewer and smaller servers to achieve similar performance.
Our test has been done without all those optimizations and we know that there is definitely a lot more room for improvements. The important thing here is that we managed to show that PostgreSQL can be made to scale to hundreds or maybe thousands of CPUs, which can cooperate in a cluster to work on the very same query.
At this point a single “master” server and a couple of shards have been used. For most cases this architecture will be sufficient. However, keep in mind that it is also possible to organize servers in a tree, which can make sense for some even more complex calculation.
Also keep in mind that PostgreSQL supports custom aggregates. The idea is that you can create your own aggregation function to do even more complex stuff in PostgreSQL.
Contact: Follow us on Twitter (@PostgresSupport) so that you can stay up to date. More cool stuff is on the way.
+43 (0) 2622 93022-0
office@cybertec.at
Nice job, looking forward to what's to come in the future of PostgreSQL. How does your approach differ to other solutions like Citus, Vitesse or Postgres-XL?
Very informative article , thanks.
Parallel execution in highload is not useful, since all cores are already busy. It's very nice to play in psql, though 🙂
At Adjust we are making increasing use of parallel execution on systems with moderate load. The idea is that you have writes come into the raw servers round robin and then aggregated and sent to systems sharded in a more useful way. These are then further aggregated before sent to the client. So we have a fairly large number of parallel processing steps to the workload.
For analytic workloads there are almost always enough ways to find enough resources to run the queries in a parallel way.